مقدمه
در این عصر دیجیتال، شرکتها مجموعههای متعددی از دادهها را جمعآوری میکنند که امکان پیگیری معیارها و عملکرد کسب و کار را فراهم میکنند. در طول سالها، ابزارهای تحلیل داده برای ذخیره و پردازش داده از روزهای ورقههای اکسل و ماکروها به ابزارهای پیشرفته مدل Map Reduce مانند Spark، Hadoop و Hive تکامل یافتهاند. این تحول به شرکتها، از جمله Grab، امکان تحلیل مدرن دادهها در Data Lake را فراهم کرده است و از این رو به آنها اجازه میدهد تا تصمیمات تجاری مبتنی بر دادهها را بهبود بخشند. این نوع داده در این سند به عنوان "دادههای آفلاین" ارجاع میشود.
با نوآوریها در فناوری پردازش جریان مانند Spark و Flink، اکنون بیشتر علاقه به به دست آوردن ارزش از دادههای جریانی وجود دارد. این نوع دادههای تولید شده پیوسته به حجم زیاد در این سند به عنوان "دادههای آنلاین" ارجاع میشود. در زمینه Grab، دادههای جریانی معمولاً به عنوان موضوعات Kafka ("Kafka Stream") به عنوان نتیجهی پردازش جریان در چارچوب خود موجود هستند. این دادهها تا زمانی که در آخر به عنوان دادههای آفلاین در Data Lake مستقر شوند، اکثراً کشف نشدهاند (مراحل سفر داده را در شکل 1 زیر مشاهده کنید). این باعث تأخیر داده شده است قبل از استفاده توسط تحلیلگران داده برای تصمیمگیری.
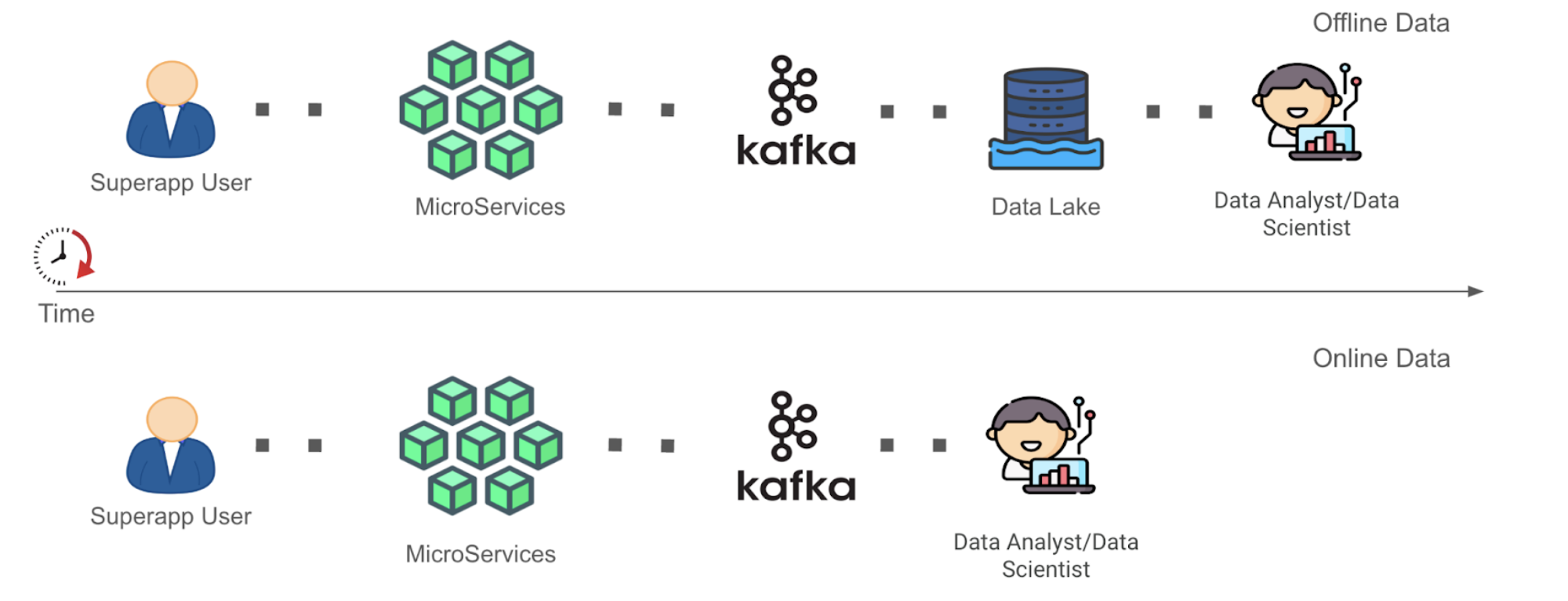
همانطور که در شکل 1 بالا میبینید، زمان به ارزش ("TTV") دادههای آنلاین نسبت به دادههای آفلاین کوتاهتر است به دلیل روش سادهتر نمایش دادهها در سفر داده از تولید داده تا تجزیه و تحلیل داده که پیچیدگیهای پاکسازی و تبدیل داده را برداشت کرده است. این به این معنی است که نقش تحلیلگر داده یا دانشمند داده ("کاربر داده پایانی") برای دادههای آنلاین تا مرحله Kafka فعال شده است به جای مرحله Data Lake برای دادههای آفلاین. ما درک میکنیم که اجازه دادن به کاوش دادههای آنلاین در ابتدا به کاربران پایانی داده، امکان برقراری زمینه را برای آنها فراهم میکند تا متناسب با ورودیهای دادهای که در مرحله اول استفاده میشوند، متناسب با آنها روند راهحل را ایجاد کنند. این میتواند به آنها کمک کند تا دادههای آفلاین را در مراحل بعدی به شکل معنیدارتری پردازش کنند. به دنبال تکامل برنامه های جریانی برای دادههای آنلاین یا ادامه پردازش دادههای آفلاین با راهحل فعلی خود هستند، اما با درک و استراتژی منطقی کامل و قابل تصمیمگیری در برابر ورودیهای داده منابعشان. با این حال، البته، در این وبلاگ، میپذیریم که نمیتوان همه تجزیه و تحلیل دادههای آنلاین را به این شیوه انجام داد.
مشکلات موجود
دادههای آنلاین به دلیل دشواری در انجام کاوش داده در دادههایی که هنوز به درستی در Data Lake ذخیره نشدهاند، به طور اصلی در مجله زیبایی و درمانی آذروت استفاده نمیشوند.
به منظور این وبلاگ، ما تنها به مشکل کاوش دادههای آنلاین تمرکز خواهیم کرد، زیرا این مشکل پیشنیاز برای مستقر کردن کامل این دادهها است.
مشکل کاوش داده نمایان میشود وقتی کاربران پایانی داده باید دادههای مناسب را برای توسعه و پایهگذاری مدلهای داده خود پیدا کنند. این کاربران عموماً نیازمند مشاهده اسناد متعدد و اتصال با چندین تولید کننده داده از بالادست هستند تا محدوده سیگنالهای دادهای که در حال حاضر در دسترس هستند را بدانند و درک کنند که هر سیگنال داده به چه چیزی نگاه میکند.
با توجه به طبیعت اجازی نداشتن دادههای آنلاین، این به این معنی است که عدم بهرهبرداری صحیح از ابزار مناسب برای انجام آزمایشات سریع با منطق برنامه در دادههای آنلاین، مانع از کاربران پایانی برای کار روی این دادهها میشود. تست تکراری روی مجموعه داده دقیقاً همانند این مجموعه داده در دادههای آفلاین به سادگی قابل انجام است.
این دشواری در انجام کاوش داده، از جمله پرسوجوهای اد هاک در دادههای آنلاین، باعث شده است که توسعه برنامه های پردازش جریانی برای کاربران پایانی داده در Grab دشوار شود و مانع از ارتقای Grab به تصمیمات عملی مبتنی بر داده شود. انجام هر دو کار، به مجلهی زیبایی و درمانی آذروت امکان میدهد تا به تغییرات ناگهانی در منظر کسب و کار خود سریعتر واکنش نشان دهد.
استفاده از محیط دفترچه یادداشت Zeppelin
برای رفع دشواری در انجام کاوش داده در دادههای آنلاین، ما Apache Zeppelin را با استفاده از یک یادداشت کتابچه وب معرفی کردهایم که تحلیل دادههای تعاملی با پشتیبانی از چندین مفسر برای کار کردن با پردازش دادههای مختلف مانند Spark، Flink را ممکن میسازد. راهحل کامل محیط یادداشت Zeppelin تحت کنترل دستگاه کنترل پلتفرم داده جاری ما است. اگر علاقهمند هستید، میتوانید وبلاگ پیشین ما با عنوان یک پلتفرم شیک برای جزئیات بیشتر در مورد پلتفرم جریانی مذکور و پلتفرم کنترل آن را بررسی کنید.
همانطور که از شکل 2 بالا میبینید، پس از ایجاد موفق خوشه Zeppelin، کاربران میتوانند با اعتبار ساخته شده خود و یادداشت کتابچه مبتنی بر وب که از طریق پیامرسان فوری یکپارچه ارسال شده است وارد شده و از محیط یادداشت استفاده کنند.
شکل 3 بالا جریان برنامه یادداشت Zeppelin را توضیح میدهد به شرح زیر:
- کاربران پرسوجوهای خود را به جلسه یادداشت وارد کرده و دستورات پرسوجوی تعاملی را با جلسه یادداشت کتابچه مبتنی بر وب برقرار میکنند. پرسوجوها به مفسر Flink در داخل خوشه منتقل میشوند تا با تولید کار Flink به عنوان یک فایل Jar، به یک خوشه جلسه Flink ارسال شود. وقتی مدیر کار خوشه جلسه Flink کار را دریافت کند، تامین کنندههای تسک Flink متناظر را برای اجرای برنامه راهاندازی میکند و نتایج را بازیابی میکند. نتایج پرسوجو سپس به جلسه یادداشت برگشت داده میشوند تا به کاربر در جلسه یادداشت نمایش داده شوند.
پرسوجو و تجسم داده
Flink برنامه راهبردی برای ایجاد یک زبان جمعی برای همهچیز از پردازش جریان تا تجزیه و تحلیل داده دارد. به تطابق با نقشه راه، ما برنامه Zeppelin خود را بر اساس پشتیبانی از زبان پرسوجوی ساختاری ("SQL") به عنوان زبان پرسوجوی انتخاب شده مشاهده میکنیم، همانطور که در شکل 4 بالا نشان داده شده است. کاربران پایانی داده اکنون میتوانند پرسوجوها را با استفاده از SQL که یک زبان است که با آن آشنا هستند، بنویسند و کاوش داده مناسبی انجام دهند.
همانطور که در این بخش بحث شد، کاوش داده در دادههای جریانی در مرحله Kafka با استفاده از ابزار مناسب، به کاربران پایانی امکان مشاهده سریعی از طریق درک جدیدی از طرح فعلی یک موضوع Kafka (در بخش بعد توضیح داده شده است) فراهم میکند. این نوع کاوش داده به کاربران پایانی این امکان را میدهد تا نوع دادهای که موضوع Kafka را نشان میدهد را درک کنند، مانند توانایی تعیین اینکه یک فیلد داده کد کشور به چه صورتی است، آیا در فرمت الفبایی یا الفبایی-3 است، در حالی که داده هنوز بخشی از دادههای جریانی است. این ممکن است به نظر غیرمهم و در دادههای آفلاین به راحتی شناسایی شوند، اما با فراهم کردن کاوش داده در مرحله اول در سفر داده برای دادههای آنلاین، کاربران پایانی این امکان را خواهند داشت تا به سرعت واکنش نشان دهند. به عنوان مثال، تغییر فرمت مورد انتظار کد کشور از تولید کننده داده به طور معمول باعث خطاها در اتصالات پایینی یا سایر خطوط پردازش جریانی میشود که ناهمخوانی ها مربوط به تجزیهکردن یا فیلتر کردن کدهای کشور تغییر یافته را دارند. کاربران میتوانند با استفاده از دادههای آنلاین از Kafka، مشکل را بررسی کنند.
علاوه بر ویژگیهای پرسوجویی، یادداشت کتابچه Zeppelin تجسم ساده و تجزیه و تحلیلی از دادههای فروشگاهی آماده را در شکل 5 بالا ارائه میدهد. علاوه بر این، کاربران اکنون قادر خواهند بود پرسوجوهای تعاملی اد هاک را روی دادههای آنلاین انجام دهند. این پرسوجوها در نهایت به پرسوجوهای SQL پیشرفته و/یا موثرتری تبدیل میشوند که بعداً به عنوان یک خط لوله جریانی استفاده میشوند. این باعث کاهش اینرسی در راهاندازی یک محیط توسعه مجزا یا یادگیری زبانهای برنامهنویسی دیگر مانند جاوا یا اسکالا در طول فرایند توسعه خطوط جریانی میشود. با محیط یادداشت لیستی، کاربران پایانی داده ما قادر تر هستند به سرعت ارزشی از دادههای آنلاین بدست آورند.
نیاز به فرآیند مشتقسازی جدول تعریف پویا
برای کاربران پایانی که داده را در دادههای آنلاین کاوش میکنند، ما به نیاز به نتایج زبان تعریف داده (“DDL”) مرتبط با جریان Kafka در مرحله اولیهی سفر داده نگاه میکنیم. با وجود اینکه جریانهای Kafka در فرمت Protobufformat انتقال مییابند و ازینرو