معرفی
Coban - یک پلتفرم جریان داده به صورت زمان واقعی برای Grab - از دو سال گذشته با استفاده از Kafka on Kubernetes with Strimzi در محیط تولید فعالیت می کند. در یک مقاله قبلی (اعتماد صفر با Kafka) ، توضیح دادیم که چگونه از Strimzi برای ارتقای امنیت ارائه خدمات جریان داده خود استفاده کردیم.
در این مقاله ، قصد داریم توضیح دهیم که چگونه تحمل خطا را در طراحی اولیه خود بهبود بخشیده ایم تا در صورتی که یک بروکر Kafka به طور غیرمنتظره متوقف شود ، دیگر نیاز به دخالت نداشته باشیم.
بیان مشکل
ما Kafka را در AWS Cloud اجرا می کنیم. برای طرح Kafka on Kubernetes که در این مقاله توصیف شده است ، ما به Amazon Elastic Kubernetes Service (EKS) ، با کارگرهایی که به عنوان کارگر خود مدیریتی بر روی Amazon Elastic Compute Cloud(EC2) پیاده شده اند ، وابستگی داریم.
برای آسان کردن عملیات خود و محدود کردن برداشت متقابل هر یک از حادثه ها ، ما دقیقاً یک کلاست Kafka برای هر کلاست EKS مستقر می کنیم. همچنین برای هر بروکر Kafka یک کارگر کامل اختصاص می دهیم. در مورد ذخیره سازی ، در ابتدا بر روی نمونه های EC2 با حجم فروش ناپایدار (NVMe) بر روی حجمهای ذخیره سازی نمونه برای عملکرد I/O بیشینه اعتماد می کردیم. همچنین ، هر کلاست Kafka از طریق یک VPC Endpoint Service خاص خارج از Virtual Private Cloud (VPC) خود قابل دسترسی است.
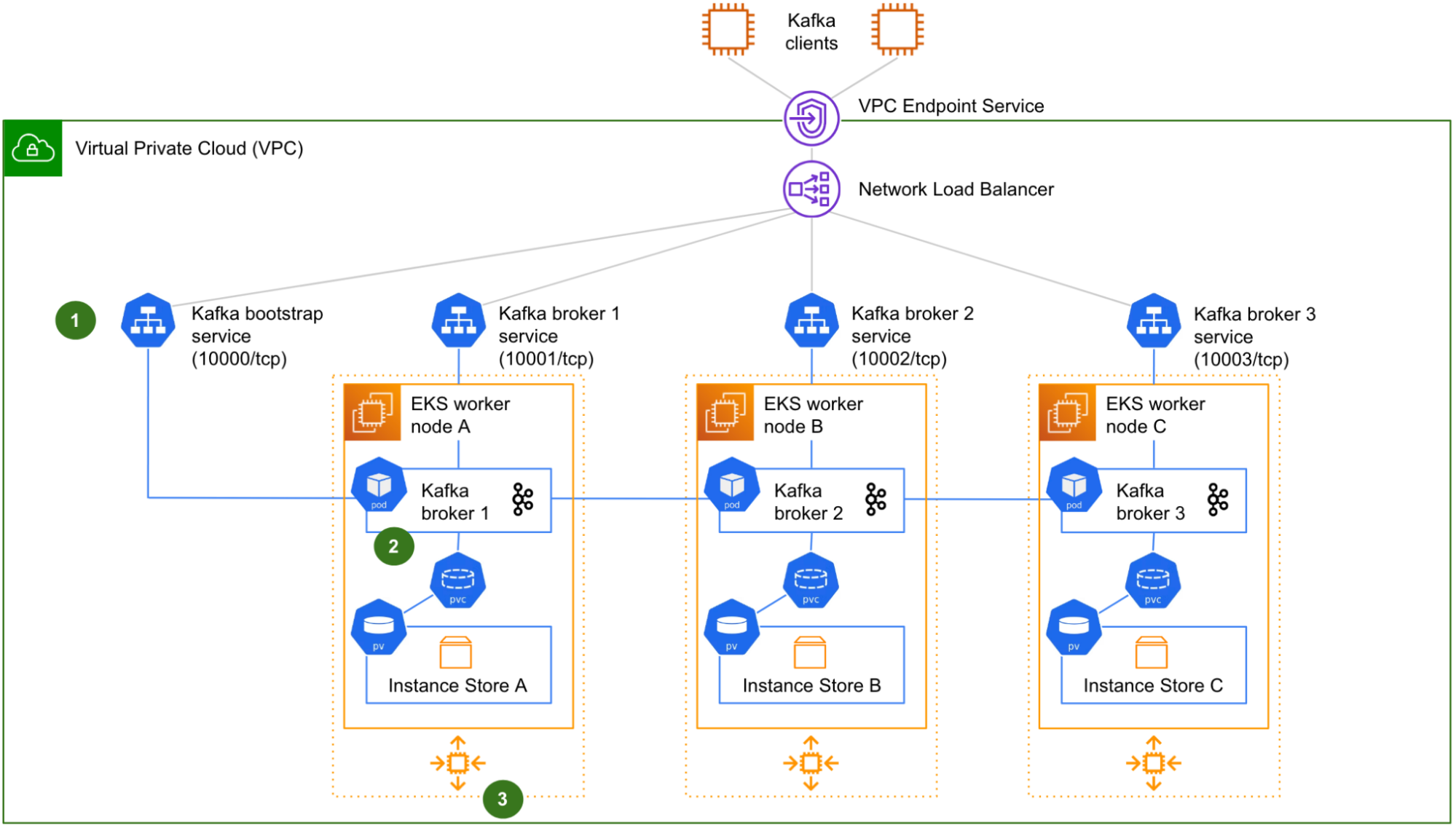
تصویر 1 نمایی منطقی از طراحی اولیه یک مجموعه Kafka 3-نود اجرا شده بر روی Kubernetes توسط Coban است. اجزای Zookeeper و Cruise-Control برای وضوح نمایش نشده است.
چهار سرویس Kubernetes وجود دارد (1): یک سرویس برای اتصال اولیه - مشتق شده به عنوان "bootstrap" - که ترافیک ورودی را به هر پاد Kafka تغییر مسیر می دهد ، به علاوه یک سرویس برای هر پاد Kafka ، برایتامین یا کاهش تعداد نت جداگانه (نیازمندی برای تولید یا مصرف از / به یک بخشی که بر روی هر پاد Kafka خاص قرار دارد). چهار گوشگیر Network Load Balancer (NLB) که بر روی چهار پورت TCP متفاوت گوش می کند ، به کلاینت های Kafka اجازه می دهد تا به سرویس bootstrap یا هر بروکر Kafka خاصی که نیاز به دسترسی دارند ، دسترسی داشته باشند. این بسیار شبیه به آنچه که قبلاً در ارائه یک مجموعه Kafka از طریق سرویس VPC Endpoint توضیح داده شده است.
هر یک از نودهای کارگر یک پاد Kafka تک را میزبانی می کند (2). حجم حافظه فروش ناپایدار (NVMe) برای ایجاد یک محل ذخیره Kubernetes Persistent Volume (PV) استفاده می شود که از طریق Kubernetes Persistent Volume Claim (PVC) به یک پاد متصل می شود.
در نهایت ، نودهای کارگر به Auto-Scaling Groups (ASG) تعلق دارند (3) ، یکی برای هر منطقه قابلیت دسترسی (AZ). Strimzi نزدیکی نود را اضافه می کند تا اطمینان حاصل شود که بروکرها به طور یکنواخت در سراسر AZ توزیع شده اند. در این طراحی اولیه ، ASG ها برای اتوماسیون مقیاس هم مورد استفاده قرار نمی گیرند ، زیرا ما می خواهیم اندازه مجموعه را تحت کنترل نگه داریم. ما تنها از ASG ها (با اندازه ثابت) برای تسهیل عملیات مقیاس دستی و جایگزینی خودکار نودهای کارگر استفاده می کنیم.
در این مرحله ، یک کلاست Kafka در حال اجرا با دو پروکسی از سه بروکر وجود دارد ، تا زمانی که یک مهندس Coban دخالت کند تا گروه هدف NLB را تنظیم کند و PVC زامبی را حذف کند (این عمل ، در نتیجه تریگر مجدد ایجاد شده توسط Strimzi ، این بار با استفاده از PV حجم نمونه جدید).
در بخش بعد ، خواهیم دید چگونه موفق شده ایم سه مشکل مذکور را برای ایجاد قابلیت تحمل خطا در طراحی خود حل کنیم.
راه حل
خاموشی آرام Kafka
برای حداقل کردن اختلال برای کلاینت های Kafka ، ازAWS Node Termination Handler(NTH) استفاده کردیم. این اجزا توسط AWS برای محیط های کوبرنتیز ارائه شده است و قادر به ساج کردن و خروج از نود کارگری است که قرار است متوقف شود. این خروج ، به نوبه خود ، شامل خاموشی آرام فرآیند Kafka است که با ارسال سیگنال SIGTERM مودبانه به همه پادهای در حال اجرای روی نود کارگری که در حال خروج است (به جای SIGKILL سختگیرانه یک خاتمه عادی) فراخوانی می شود.
رویدادهای خاتمه که توسط NTH گرفته می شوند:
- عملیات کوچک شدن توسط یک ASG.خاتمه دستی یک نمونه.رویدادهای نگهداری AWS ، به طور معمول نمونه های EC2 جدول زمانبندی شده برای بازنشستگی آینده.
این برای بیشتر از اختلالاتی که خواهد شد مواجه شدن از سمت کلاینت هایمان در زمان های عادی و عملیات نگهداری مشترک مانند ختم کردن یک نود کارگر برای تازه کردن آن کافی است.
NTH دارای دو حالت است: Instance Metadata Service (IMDS) و Queue Processor. ما تصمیم گرفتیم از حالت دوم استفاده کنیم زیرا قادر است مجموعه گسترده تری از رویدادها را دریافت کند و توانایی تحمل خطا را گسترش دهد.
عملیات کوچک شدن توسط یک ASG
تصویر 3 نشان می دهد که NTH با Queue Processor در حال عمل است و چگونه به یک عملیات کوچک شدن واکنش نشان می دهد (معمولاً در طول یک عملیات نگهداری شروعی به صورت دستی فعال می شود):
- همزمان ، یک رویداد تکرار عمرچرخه به یک صف Amazon Simple Queue Service(SQS) صادر می شود. در تصویر 3 ، ما رویدادهای EC2 را همچنین واقعی (مانند ختم دستی یک نمونه ، رویدادهای نگهداری AWS و غیره) که از طریق Amazon EventBridge تردد می کنند و در نهایت در همان صف SQS خاتمه می یابند ، مادرید کرده ایم. در دو بخش بعدی ، رویدادهای EC2 را بررسی خواهیم کرد.