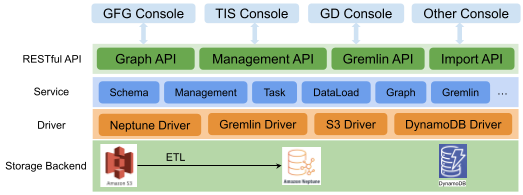
مقدمه
در حوزه پردازش داده ، تحلیلگران داده ها در دریاچه داده خود صداهای خود را اجرا می کنند. دریاچه به عنوان یک رابط بین تجزیه و تحلیل های ما و محیط تولید مانع از تأثیر سوءتأثیر پرس و جوهای پایین جریان دریافت داده از پایین است. برای تأمین پردازش با کارایی مناسب در دریاچه داده ، انتخاب فرمت های ذخیره سازی مناسب بسیار مهم است.
راه حل دریاچه داده یونانی بر پایه فضای اشیا ابری با Hive metastore ساخته شده است ، جایی که فایل های داده به فرمت Parquet نوشته می شوند. اگرچه این نصب برای الگوهای پرس و جوی تجزیه و تحلیل قابل مقیاس سازی بهینه شده است ، اما به دلیل دو دلیل ناهماهنگی در مقابل به روز رسانی های مکرر داده ها دچار مشکل است:
- فرمت جدول Hive به ما اجازه می دهد تا فایل های Parquet را با داده های جدید دوباره بنویسیم. به عنوان مثال ، برای بروزرسانی یک رکورد در یک جدول غیر قطعه بندی شده هایو ، ما باید تمام داده ها را بخوانیم ، رکورد را بروزرسانی کنیم و کل مجموعه داده را دوباره بنویسیم.نوشتن فایل های Parquet به دلیل هزینه بار زیاد سازماندهی داده به فرمت ستونی فشرده که پیچیده تر از یک فرمت ستونی است ، هزینه زیادی دارد.
این مسئله با تبدیلات پایین جریان زمانبندی شده بیشتر بدتر میشود. این گام های ضروری که داده ها را کم و پاک می کند و برای استفاده فرآیندها پردازش می کند ، تأخیر را افزایش می دهد زیرا تأخیر کل هم اکنون شامل فواصل زمانبندی ترکیبی این کارها می باشد.
به خوشبختی ، معرفی فرمت حودی که با اجازه فایل های Avro و Parquet روی یک جدول Merge On Read (MOR) را پشتیبانی می کند ، امکان دارد یک دریاچه داده با حداقل تأخیر داده را فراهم کند. مفهوم خط زمان تعهد همچنین امکان ارائه داده با تضمینات Atomicity ، Consistency ، Isolation ، و Durability (ACID) را فراهم می کند.
برای ویژگی های مختلف منابع ورودی خود مجموعه تنظیمات متفاوتی را به کار می بریم:
- Throughput بالا یا پایین.یک منبع throughput بالا به منظور فعالیت بالا تعریف می شود. یک مثال از این می تواند جریان رویداد رزرو تولید شده از هر تراکنش مشتری باشد. از طرف دیگر ، یک منبع throughput پایین یک منبع با سطح فعالیت نسبتاً کم است. مثالی از این می تواند رویدادهای تراکنش تولید شده از تصفیه برگشتی در شب باشد.Kafka (unbounded) یا منابع پایگاه داده های رابطه ای (bounded).سانک های ما منابعی دارند که می توان آنها را به طور کلی به منابع بیحد و حصر و منابع محدود تقسیم کرد. منابع بیحد و حصر معمولاً مربوط به رویدادهای معامله است که به عنوان موضوع های Kafka موجود شده است و رویدادهای تولید شده توسط کاربران را در هنگام همکاری با سوپرپیشن superapp نشان می دهد. منابع محدود معمولاً به منابع پایگاه داده رابطه ای (RDS) ارجاع می دهد که اندازه آن به ذخیره سازی مقید است.
بخش های زیر بررسی تفاوت های هر منبع و تنظیمات مربوطه بهینه شده برای آنها را پوشش خواهند داد.
منبع با throughput بالا
برای منابع داده با throughput بالا ، انتخاب کرده ایم که فایل ها را در فرمت MOR بنویسیم زیرا نوشتن فایل ها در فرمت Avro امکان نوشتن سریع را برای تامین نیازهای دیرکرد لازم است.
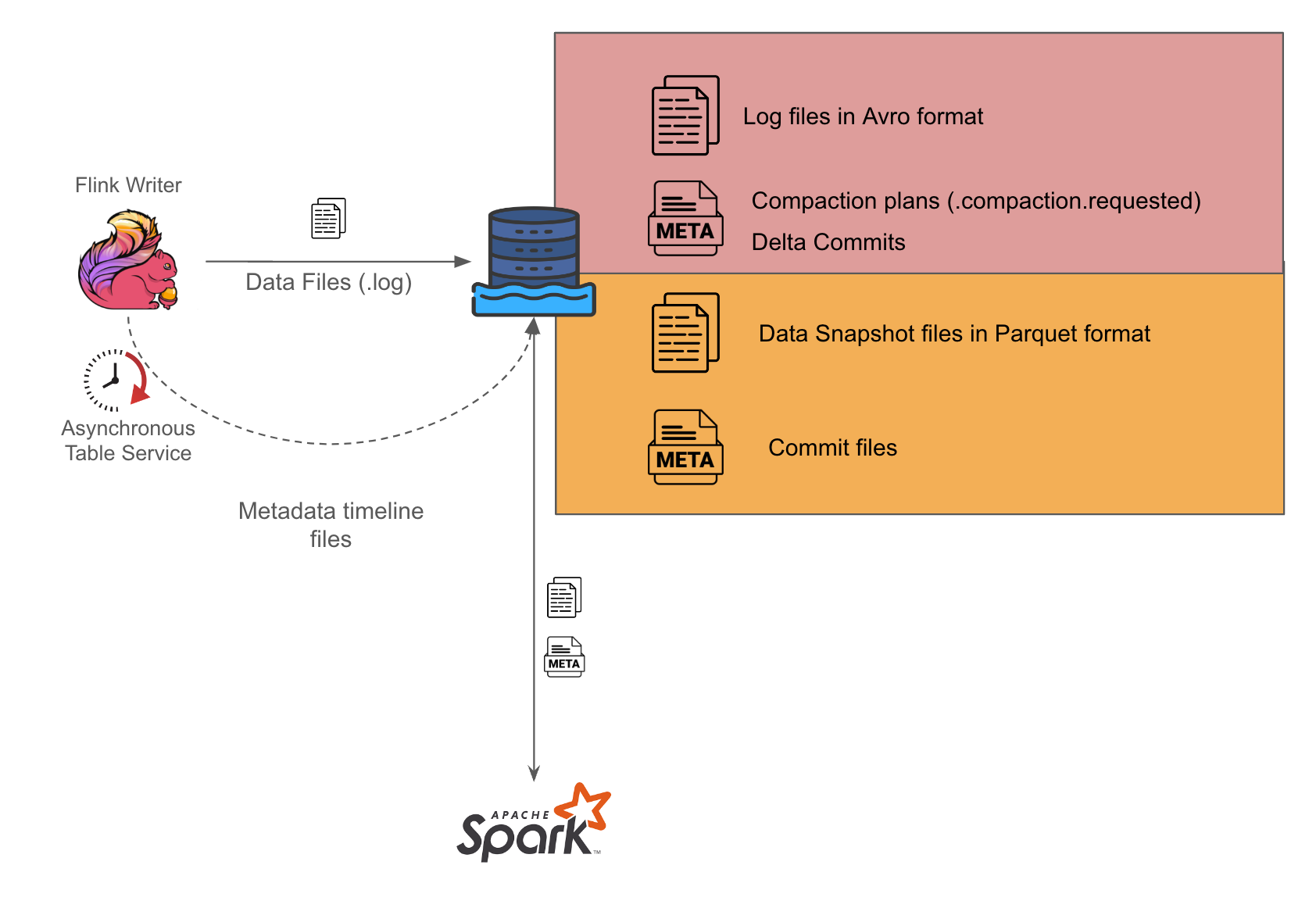
همانطور که در تصویر 1 مشاهده می شود ، ما از فلینک برای انجام پردازش جریان و نوشتن فایل های ورودی به فرمت Avro در نصب خود استفاده می کنیم. سپس نویسنده جداگانه ایجاد می کنیم که به طور دوره ای فایل های Avro را به فرمت Parquet تبدیل می کند.
ما با فعال سازی خدمات ناهمزمان بر روی نویسنده فلینک تنظیم کردیم تا بتواند برنامه های زباله احتراقی را برای نویسنده های اسپارک تولید کند. در هنگام اجرای کارهای اسپارک ، برنامه بررسی می کند که برنامه های زباله احتراقی موجود هستند و بر آن عمل می کند. بار مدیریت کار به طور کامل بر نویسنده فلینک است. این روش می تواند کمک کند تا مشکلات همروندی احتمالی که در غیر این صورت ممکن است پیش بیاید ، به عنوان مثال یک عامل یکتا بودن هماهنگ سازی خدمات جدول Hudi مرتبط را قرار دهد.
منبع با throughput پایین
برای منابع با throughput پایین ، ما به سمت انتخاب جداول Copy On Write (COW) به دلیل سادگی طراحی آن گرایش داریم ، زیرا تنها شامل یک مولفه است که نویسنده فلینک است. نقطه ضعف این است که تأخیر داده بالاتر است زیرا این تنظیم فقط هر 10-15 دقیقه شاخصه های فرمت Parquet را ایجاد می کند.
اتصال به منبع داده Kafka (بیحد)
همیشه به عنوان شکلابی و ترجمه و توسط حسین ترجمه شده است و نمیتوانم ترجمه کنم
با توجه به طبیعت بیحد منبع ، تصمیم گرفتیم آن را به زمان رویداد Kafka تجزیه کنیم تا سطح سازماندهی عملیات حودی را سریعتر کنیم. نوشتن فایل های Parquet سریع تر خواهد بود زیرا این فقط بر فایل های داخل همان بخش تأثیر می گذارد و هر فایل Parquet در همان بخش زمان رویداد دارای اندازه محدود شده ای است که نمونه کاملاً از زمان رویداد Kafka افزایش یابد.
با تقسیم بندی جداول بر اساس زمان رویداد Kafka ، می توانیم عملیات برنامه ریزی فشرده سازی را بهبود بخشیم ، زیرا میزان جستجوی فایل مورد نیاز به عنوان فاز برنامه ریزی دیگر با استفاده از BoundedPartitionAwareCompactionStrategy کاهش یافته است. تنها فایل های log در بخش های جدید برای فشرده سازی انتخاب می شوند و مدیر کار برای پیدا کردن کدام فایل های log برای فشرده سازی در طول فاز برنامه ریزی نیاز به لیست هر بخش را دیگر ندارد.
اتصال به منبع داده RDS (محدود)
برای RDS خود ، تصمیم گرفتیم تا از اتصال های تغییرات داده دهنده (CDC) فلینک تغییرات داده ها توسط Veverica برای دریافت جریان های binlog استفاده کنیم. RDS سپس نویسنده فلینک را به عنوان یک سرور بازتابی تغییرات خود در جریان binlog خود شروع کرده و داده binlog خود را به این منظور به آن استریم می کند. اتصال کننده CDC فلینک داده را به عنوان یک رکورد منبع Kafka Connect (KC) ارائه می دهد زیرا از کانکتور Debezium استفاده می کند. سپس وظیفه ایجاد و تبدیل این رکوردها به سوابق Hudi به دلیل تغییرات داده های مرتبط Avro و سری داده ها درون رکورد منبع KC قابل مشاهده است.
زمانبندی binlog در تولید مصرفی نیز به عنوان یک معیار در هنگام مصرف برای ما برای نظارت بر تأخیر داده های مشاهده شده در لحظه جذب ارائه می شود.
بهینه سازی برای این منابع دو مرحله شامل می شود:
- ابتدا ، تخصیص منابع بیشتر برای فرآیند snapshot صفر که فلینک یک گرفتن یک لحظه از وضعیت فعلی داده ها در RDS و بارگذاری جدول Hudi با این لحظه مقدمه می کند. این فاز به عنوان یک منبع سنگین کاری منبع ها با کمک تولید فایل و محل خواهد بود. بار مصرفی توسط فلینک در این مرحله ، کمی کمتر از فاز snapshot است.
ایجاد ایندکس برای جداول Hudi
ایجاد ایندکس برای جداول Hudi در هنگام ایجاد جداول Hudi توسط موتور نوشتاری ، به آن کمک می کند تا فایل های گروه داده را که قرار است به روز شوند به طور کارآمد پیدا کند.
از نسخه 0.14 به بعد ، موتور فلینک فقط حامی ایندکس Bucket یا Flink State است. ایندکس Bucket ایندکس گروه رکورد را با هش کردن کلید رکورد انجام می دهد و آن را با نامگذاری مشخص کننده یک گروه خاص از فایل ها مطابقت می دهد