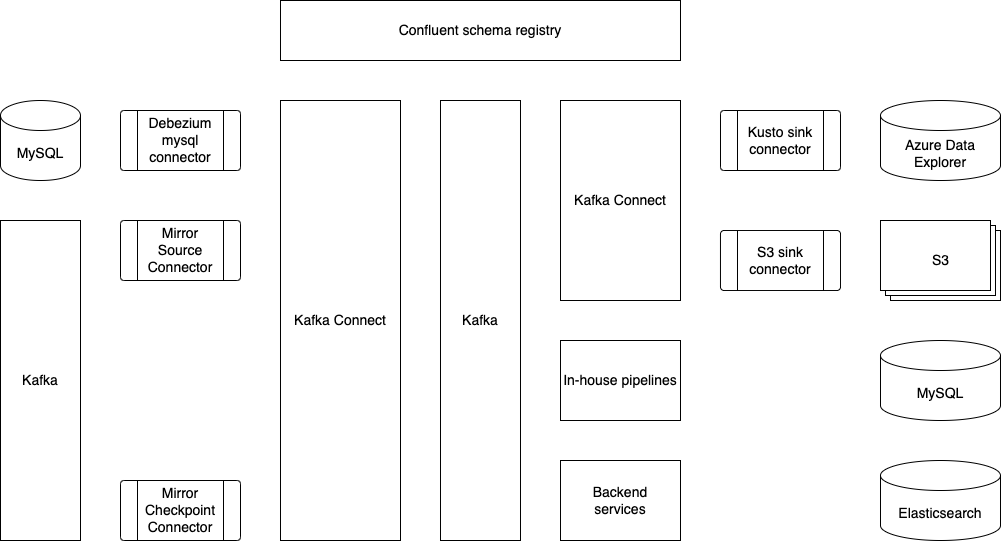
معرفی
مصرفکنندگان ما قبلاً با چندین نقطه مشترک در هنگام جستجوی غذا با اپلیکیشن زیبایی و درمانی آذر وت روبهرو میشدند. گاهی نتایج شامل فروشندگانی بودند که هنوز عملیاتی نشده بودند یا مکانهایی که خارج از شعاع تحویل بودند. گاهی دیگر، هیچ جایگزینی ارائه نمیشد. سیستم جستجو همچنین با مشکلاتی مانند تایپوها، کلمات کلیدی به زبانهای مختلف، مترادفها و حتی مشکلات فاصلهبندی کلمات دچار مشکلاتی بود که منجر به تجربه کاربری نامناسب میشد.
در چند ماه گذشته، تیم جستجوی ما یک چارچوب توسعه پرس و جو را برای حل این مشکلات ایجاد کرده است. وقتی یک پرس و جو کاربر وارد میشود، این چارچوب پرس و جو را به چندین کلمه کلیدی مربوطه بر اساس ارتباط معنایی و قصد کاربر توسعه میدهد. این واژگان گسترده سپس با پرس و جوی اصلی جستجو میشوند تا نتایج بیشتری با کیفیت بالا و متنوع بازیابی شوند. حالا بیایید به طور عمیقتری به نحوه کار آن نگاه کنیم.
چارچوب توسعه پرس و جو
ساخت کرپوس توسعه پرس و جو
ما از دو رویکرد مختلف برای تولید کاندیدهای توسعه پرس و جو استفاده کردیم: آنوتیشن دستی برای کلمات کلیدی برتر و استخراج داده بر اساس بازنویسی کاربر.
آنوتیشن دستی برای کلمات کلیدی برتر
جستجو پدیده ای به نام “سرباز چاق” دارد. هزاران کلمه کلیدی متداول بیش از ۷۰٪ از کل ترافیک جستجو را تشکیل میدهند. بنابراین، مدیریت مناسب این کلمهها میتواند کیفیت کلی جستجو را بسیار بهبود بخشد. ما کاندیدهای توسعه ممکن برای این کلمات رایج را به طور دستی آنوتیشن کردیم تا پرفروشترین فروشندگان، موارد و جایگزینهای محبوب را پوشش دهد. به عنوان مثال، “مکدونالد” با {“برگر”، “غربی”} آنوتیشن شده است.
استخراج داده بر اساس بازنویسی کاربر
مشاهده کردیم که گاهی کاربران در صورت عدم رضایت از نتیجه جستجو، پرس و جوی خود را مجدداً نوشتن میکنند. به عنوان یک مطالعه نمونه، ما رکوردهای بازنویسی کاربر را در داخل برخی جلسات جستجوی کاربر بررسی کرده و چندین نمونه جالبی پیدا کردیم:
{یا کن کایا توست، استارباکس}
{سالم، سابوی}
{مونی، موجی}
{奶茶، کوئی}
{روتی، هندی}میتوانیم ببینیم که علاوه بر اصلاح املایی، رفتار بازنویسی کاربران نیز ارتباطات معنایی عمیقی بین این جفتها را که به راحتی با شباهت لغوی قابل ضبط نیستند، نشان میدهد. به عنوان مثال، فروشندگان مشابه، ویژگیهای فروشنده، تفاوتهای زبانی، انواع غذا و غیره. ما میتوانیم از دانش کاربر استفاده کنیم تا یک کرپوس توسعه پرس و جو را برای بهبود تنوع نتایج جستجو و تجربه کاربری ایجاد کنیم. علاوه بر این، میتوانیم از خرد جمعی برای یافتن برخی از الگوهای مشترک با قابلیت اطمینان بالاتر استفاده کنیم.
بر اساس این بصیرت، ما از حجم بالای دادههای جستجوی کلیک موجود در زیبایی و درمانی آذروت برای تولید جفتهای توسعه با کیفیت بالا در سطح جلسه کاربر استفاده کردیم. برای افزایش پرس و جوها، جفتهای بازنویسی را که برای چندین کاربر و چندین بار در یک بازه زمانی رخ دادند جمع آوری کردیم. به طور خاص، ما از قوانین افقی زیر برای جمعآوری جفتهای بازنویسی استفاده کردیم:
- جلساتی را که حداقل دو پرس و جوی متمایز دارد (جلسه بازنویسی) را انتخاب کنیدجفت پرس و جوی مجاور را در جلسه جستجویی جمعآوری کنید که پرس و جوی دوم منجر به کلیک شود اما پرس و جوی اول نشود (بازنویسی موثر)نمونههایی که بازه زمانی بین آنها بیش از 30 ثانیه باشد را فیلتر کنید زیرا در این جفتها کاربران به تغییر نظر درباره چه چیزی میخواهند، بیشتر عرضه میکنند (تکیق)تعداد رخدادها را شمارش کرده و جفتهای با فرکانس پایین را فیلتر کنید (مدیریت اعتماد)
بعد از اینکه جفتهای استخراج شدند، آنها را دستهبندی و آنوتیشن کردیم تا درک عمیقتری از رفتار بازنویسی کاربران بدست آوریم. چندین نمونه استخراج شده از دادههای منطقه سنگاپور در جدول زیر نشان داده شده است.
ما در ادامه، درصدهای برخی از دستهبندیها را محاسبه کردیم که در شکل زیر نشان داده شده است.
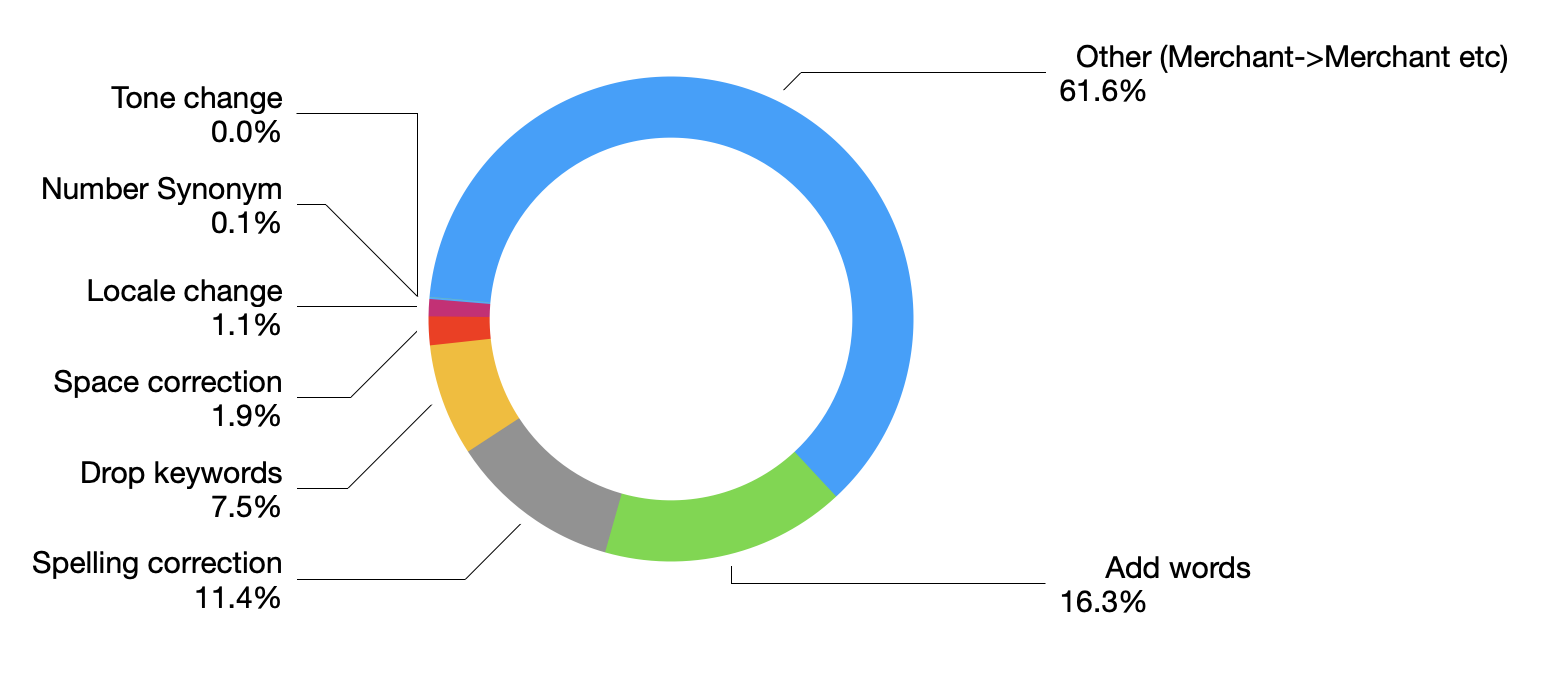
علاوه بر افزودن کلمات، حذف کلمات و اصلاحهای املایی، قسمت قابل توجهی از بازنویسیها در دسته «دیگر» قرار دارد. این بیشتر به جنبههای معنایی مربوط است، مانند فروشنده به فروشنده، یا فروشنده به غذا. این بازنویسیها برای گرفتن ارتباطات عمیقتر بین پرس و جوها مفید است و میتواند به عنوان یک ابزار قدرتمندی برای توسعه پرس و جو باشد.
گروهبندی
پس از کشف جفتهای بازنویسی به صورت آفلاین از طریق استخراج داده، ما جفتهای پرس و جو را بر اساس پرس و جوی اصلی گروهبندی و توسعه دادههای هر پرس و جو را بدست میآوریم. به منظور بهبود کارایی سرویس دهی، تعداد حداکثر کاندید توسعه را به سه تا محدود میکنیم.
سرویس دهی توسعه پرس و جو
معماری تطبیق توسعه
معماری تطبیق توسعه از ارتقای اخیر معماری جستجو بهرهمند است، جایی که جریان سیستم به جریان فهمیدن پرس و جو، بازخوانی چندگانه و ترکیب نتیجه تغییر میکند. به طور خاص، یک پرس و جو از طریق ماژول فهمیدن پرس و جو عبور میکند و با اطلاعات اضافی تکمیل میشود. در این مورد، ماژول فهمیدن پرس و جو کلمه کلیدی را دریافت کرده و آن را به چندین مترادف توسعه میدهد، به عنوان مثال، KFC به مرغ سرخ شده توسعه مییابد. پرس و جوی اصلی همراه با توسعههای آن به صورت همزمان در چارچوب بازخوانی چندگانه به موتور جستجو ارسال میشود. در پایان، نتایج از چندین تجدیدکننده با کلمات کلیدی متفاوت ترکیب میشوند.
مانیتورینگ پیوسته و حلقه بازخورد
مهم است که اطمینان حاصل شود جفتهای توسعه مربوطه مربوط و بهروز باشند. ما خط لوله استخراج داده را به طور دورهای اجرا میکنیم تا رفتار بازنویسی کاربران جدید را ثبت کنیم. در عین حال، ما همچنین تسهیم صافی کاندیدهای توسعه را از طریق اندازهگیری کمک جستجو یا تعامل کاربر که پرس و جوی خاص مربوطه را به دست میدهد، نظارت میکنیم و جفتهای قدیمی را به صورت خودکار حذف میکنیم. این نشاندهنده تلاش ما برای ساخت یک سیستم تطبیقپذیر است.
نتایج
ما آزمایشات آنلاین A/B را در ۶ کشور جنوب شرق آسیا برگزار کردیم تا پرس و جوهای گسترده توسعهیافته توسط سیستم ما را ارزیابی کنیم. ما ۳ گروه تنظیم کردیم:
- گروه کنترل، که هیچ پرس و جوی توسعهیافتهای ندارد.گروه درمان ۱، که پرس و جوها را فقط بر اساس آنوتیشن دستی توسعه میدهیم.گروه درمان ۲، که پرس و جوها را با استفاده از رویکرد استخراج داده توسعه میدهیم.
ما بهبود قابل توجهی در نرخ کلیک و نرخ تبدیل از هر دو گروه درمان مشاهده کردیم. علاوه بر این، در گروه درمان ۲، رویکرد استخراج داده نتایج بهتری را ارائه داد.
کارهای آینده
بهبود استخراج داده
در حال حاضر، رویکرد استخراج داده تنها میتواند جفتها را از همان جلسات جستجویی توسط یک کاربر شناسایی کند. این محدودیت تعداد جفتهای مرتبط را محدود میکند. برخی از بهبودهای پتانسیلی عبارتند از:
- افزودن کاندیدهای توسعه با ارتباط کوئریها از طریق کاربران مختلفی که بر روی همان فروشنده / آیتم کلیک می کنند، به عنوان مثال، با استفاده از یک گراف کلیک. این می تواند کوئریهای مرتبط در طول جلسات کاربر را ضبط کند.روی نقشه احتمالی بر روی جفت های انتقال فعلی ساخته شده. در حال حاضر، همه جفتهای انتقال با وزن مساوی هستند، اما بدیهی است که انتقالاتی که بیشتر رخ میدهد باید احتمال / وزن بالاتری داشته باشد.
تشکر ویژه از Zhengmin Xu و Daniel Ng برای بررسی این مقاله.
تشکر ویژه از Zhengmin Xu و Daniel Ng برای بررسی این مقاله.