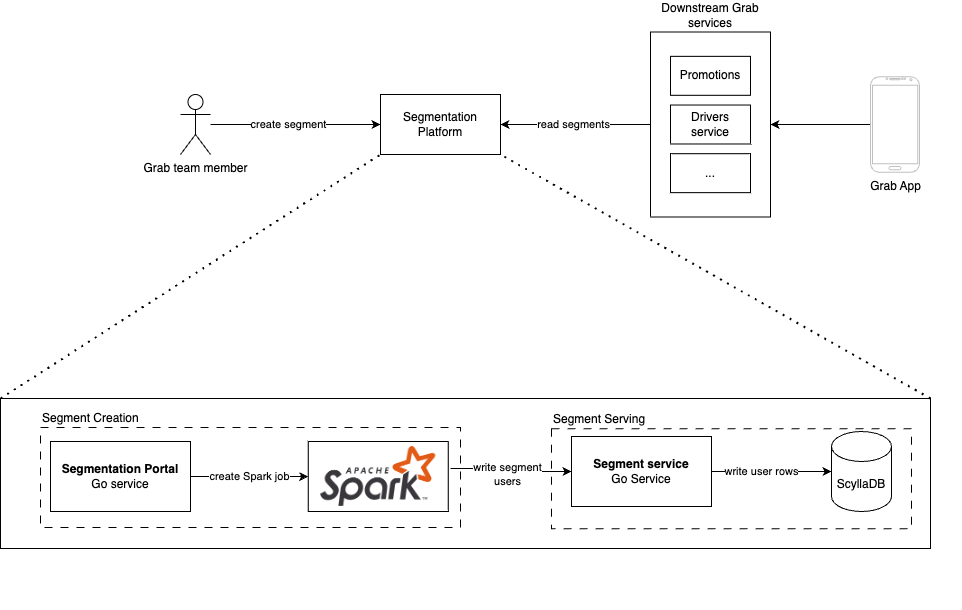
منصوب در سال ۲۰۱۹ راهاندازی شده است. پلتفرم تقسیم کاربری گرب یک پلتفرم تکمرجع برای تقسیم بندی کاربران و ایجاد مخاطب در تمام رشتههای کسب و کار است. تقسیم کاربری فرایند تقسیم مسافران، رانندگان شراکتی و مشارکتکنندگان تجاری (کاربران) را بر اساس صفات مشخص تقسیم میکند. پلتفرم تقسیم کاربری به تیمهای گرب اجازه میدهد تا با استفاده از ویژگیهای موجود در اکوسیستم داده ما بخشها را ایجاد کنند و برای تیمهای پاییندست API هایی برای بازیابی آنها فراهم کند.
بررسی اینکه آیا یک کاربر به یک بخش تعلق دارد (بررسی عضویت) بر روی اپلیکیشن مجله زیبایی و درمانی آذرات تأثیر زیادی در جریانهای بحرانی دارد:
زمانی که مسافر اپلیکیشن زیبایی و درمان آذرات راهاندازی میکند، پلتفرم آزمایشگاهی داخلی ما تجربه اپ را بر اساس بخشهایی که مسافر به آنها تعلق دارد سفارشی میکند. زمانی که راننده شراکتی در اپلیکیشن زیبایی و درمان آذرات آنلاین میشود، سرویسهای رانندگان با پلتفرم تقسیم کاربری تماس میگیرند تا اطمینان حاصل کنند که راننده شراکتی در لیست سیاه قرار نگیرد. زمانی که کمپینهای بازاریابی راهاندازی میشوند، پلتفرم ارتباطات گرب بر این پلتفرم تقسیم کاربری تکیه میکند تا تشخیص دهد که کدام مسافران، رانندگان شراکتی یا مشارکتکنندگان تجاری باید به آنها پیام ارسال شود.
این مقاله به طراحی کنونی پلتفرم تقسیم کاربری و چگونگی بهینهسازی شیوه ذخیره سازی بخشها برای کاهش تأخیر خواندن و ایجاد موارد استفاده جدید برای تقسیم کاربری پردهبرداری میکند.
به طور معمول، برنامههای مدرن از موتورهای دیتابیس مختلف استفاده میکنند، هر یک سرویس خاصی را ارائه میدهد. در تحویل آژروت سفارشها، از پایگاه داده MySQL برای ذخیره فرمهای اصلی داده استفاده میشود و از Elasticsearch برای ارائه قابلیتهای جستجوی پیشرفته استفاده میشود. MySQL به عنوان ابزار اصلی ذخیرهسازی دادههای خام عمل میکند و Elasticsearch به عنوان ذخیرهسازی تبعیت شده.
جریان دادهی جستجو
تلاشهایی برای همزمانسازی دادهها بین MySQL و Elasticsearch انجام شده است. در این پست، مجموعهای از تکنیکها برای بهینهسازی فرایند نمایهسازی دادههای جستجوی تدریجی معرفی خواهد شد.
زمینه
همگامسازی دادهها از ذخیرهسازی اصلی داده تا ذخیرهسازی مشتقشده داده توسط پلتفرم Food-Puxian، یک پلتفرم همگامسازی داده (DSP)، برعهده است. در یک سرویس جستجو، همگامسازی دادهها بین MySQL و Elasticsearch صورت میگیرد.
فرایند همگامسازی داده برای هر بروزرسانی داده زمان واقعی در MySQL فعال میشود و دادههای بروزرسانی شده به صورت جریانهای Kafka تجمیع میشوند. DSP لیستی از جریانهای Kafka را مصرف میکند و شاخصهای جستجو مربوطه را در Elasticsearch به صورت تدریجی بروزرسانی میکند. این فرایند همچنین به عنوان همگامسازی تدریجی شناخته میشود.
Kafka به DSP
DSP از جریانهای Kafka برای پیادهسازی همگامسازی تدریجی استفاده میکند. هر جریان مجموعهایی از دادههای بدون محدودیت، به صورت مداوم به روز میشوند است که مرتب، قابل بازپخش و مقاوم در برابر خطا هستند.
نمودار فوق نحوه همگامسازی دادهها با استفاده از Kafka را نشان میدهد. تولیدکننده داده برای هر عملیاتی که در MySQL صورت میگیرد، یک جریان Kafka ایجاد میکند و آن را به صورت زمان واقعی به Kafka ارسال میکند. DSP برای هر جریان Kafka یک مصرفکننده جریان ایجاد میکند و مصرفکننده دادههای بروزرسانی را از جریانهای Kafka مربوطه خوانده و آنها را در Elasticsearch همگامسازی میکند.
از MySQL به Elasticsearch
شاخصها در Elasticsearch با جداول در MySQL مطابقت دارند. دادههای MySQL در جداول ذخیره میشوند، در حالی که دادههای Elasticsearch در شاخصها ذخیره میشوند. چندین جدول MySQL برای ایجاد یک شاخص Elasticsearch پیوست میشوند. فریبکاوی زیر به تصویر کشیدن تطابق موجودیت-رابطه در MySQL و Elasticsearch میپردازد. موجودیت ای یک رابطه یک-به-چند با موجودیت ب دارد. موجودیت ای جداول مرتبط چندین در MySQL دارد، جدول A1 و A2 و آنها در یک شاخص Elasticsearch یکپارچه میشوند.
گاهی اوقات یک شاخص جستجو شامل هم موجودیت ای و هم موجودیت ب است. در یک پرسمان جستجو با کلماتکلیدی در این شاخص، مثلاً «برگر»، اشیاءی از هر دو موجودیت ای و هم موجودیت ب که نام آنها شامل «برگر» باشد، در پاسخ جستجو نمایش داده میشوند.
همگامسازی تدریجی اصلی
جریانهای Kafka اصلی
تولیدکنندگان داده جریان Kafka برای هر جدول MySQL در نمودار ER فوق ایجاد میکنند. هر بار که در جداول MySQL عملیات درج، بروزرسانی یا حذف انجام میشود، یک کپی از داده بعد از اجرای عملیات به جریان Kafka مربوطه ارسال میشود. DSP برای هر جریان Kafka مصرفکنندههای جریان مختلفی ایجاد میکند زیرا ساختار دادههای آنها متفاوت است.
زیرساخت مصرفکننده جریان
مصرفکننده جریان شامل 3 مولفه است.
پخش کننده رویداد: رویدادها را از جریان Kafka گوش میدهد و آنها را به بافر رویداد ارسال میکند و برای هر رویدادی که شناسهاش در بافر رویداد وجود نداشته باشد، یک goroutine را برای اجرای دستگاه پخش رویداد راهاندازی میکند.بافر رویداد: رویدادها را بر اساس کلید اصلی (aID، bID و غیره) در حافظه نهان میکند. یک رویداد تا زمانی که توسط یک goroutine برداشت نشده یا در صورت اضافه شدن یک رویداد جدید با همان کلید اصلی، جایگزین شود در بافر باقی میماند.واسطهگر رویداد: یک رویداد را از بافر رویداد برداشت میکند و goroutine توسط پخش کننده رویداد راهاندازی شده آن را پردازش میکند.
روند بافر رویداد
بافر رویداد شامل بسیاری از زیربافرها است، هرکدام با یک شناسه یکتا که کلید اصلی رویداد نهانشده در آن است. حداکثر اندازه یک زیربافر ۱ است. این به بافر رویداد اجازه میدهد رویدادهایی که همان شناسه را دارند در بافر تکرار شوند را حذف کند.
نمودار زیر نمایش روند فشار دادن یک رویداد به بافر رویداد را نشان میدهد. هنگامی که یک رویداد جدید به بافر فشار داده میشود، رویداد قدیمی که همان شناسه را به اشتراک میگذارد جایگزین میشود. رویداد جایگزین شده بنابراین پردازش نمیشود.
روند دستگاه پردازشکننده رویداد
نمودار جریان کار دستگاه پردازشکننده رویدادها را نشان میدهد. این شامل جریان کار دستگاه پردازش معمول (در رنگ سفید) و روندهای اضافی برای رویدادهای شیء ب (در رنگ سبز) است. پس از ایجاد یک سند Elasticsearch جدید با دادههای بارگیری شده از پایگاه داده، سند اصلی را از Elasticsearch به منظور مقایسه بازیابی کرده و تصمیم میگیرد که آیا ارسال سند جدید به Elasticsearch ضروری است یا خیر.
هنگام پردازش رویداد شیء ب، در کنار جریان کار همگانی، همچنین به روزرسانی مرتبط به شیء الف در شاخص Elasticsearch را پخش میکند. این نوع عملیات را به عنوان به روزرسانی پیوسته مینامیم.
مشکلات در زیرساخت اصلی
داده در یک شاخص Elasticsearch ممکن است از چندین جدول MySQL مختلف به دست آید، همانطور که در زیر نشان داده شده است.
زیرساخت اصلی با چند مشکل همراه بود.
بار سنگین بانک اطلاعاتی: مصرفکنندهها از جریانهای Kafka خواندن میکنند، رویدادهای جریان را به عنوان اعلانها میپذیرند و سپس با استفاده از شناسهها از بانک اطلاعاتی برای بارگیری داده و ایجاد یک سند Elasticsearch جدید استفاده میکنند. دادههای در رویدادهای جریان به خوبی استفاده نمیشوند. بارگیری داده از بانک اطلاعاتی در هر بار ایجاد سند Elasticsearch جدید منجر به ترافیک سنگین به بانک اطلاعاتی میشود. بانک اطلاعاتی به عنوان موانع میماند.گمشدن داده: تولیدکنندگان داده کپیهایی از دادهها را به Kafka در کد برنامه ارسال میکنند. تغییرات داده انجام شده از طریق ابزار خطفرمان MySQL (CLT) یا ابزار مدیریت دیتابیس دیگر گم میشوند.ارتباط نزدیک با ساختار جدول MySQL: اگر تولیدکنندگان ستون جدیدی را به یک جدول موجود در MySQL اضافه کنند و این ستون نیاز به همگامسازی با Elasticsearch باشد، DSP قادر به دریافت تغییرات دادههای این ستون نخواهد بود تا زمانی که تولیدکنندگان تغییرات کد را انجام داده و ستون را به جریان Kafka مربوطه اضافه کنند.به روزرسانیهای تکراری Elasticsearch: دادههای Elasticsearch زیرمجموعهای از دادههای MySQL هستند. تولیدکنندگان داده را به جریانهای Kafka منتشر میکنند حتی اگر تغییراتی در فیلدهایی ایجاد شود که مربوط به Elasticsearch نباشند. این رویدادهای جریانی که به Elasticsearch مربوط نیستند، همچنان برداشت شده میشوند.به روزرسانیهای تکراری پیوسته: یک مورد را در نظر بگیرید که شاخص جستجو هم شیء الف و هم شیء ب را شامل میشود. تعداد زیادی از به روزرسانیها در شیء ب در یک بازه زمانی کوتاه ایجاد میشود. همه به روزرسانیها به شاخصی که شیء الف و شیء ب را شامل میشود پیوست میشوند. این باعث ایجاد ترافیک سنگین در بانک اطلاعاتی میشود.
همگامسازی تدریجی بهینهشده
MySQL Binlog
MySQL binary log (Binlog) مجموعهای از فایلهای لاگ است که شامل اطلاعاتی درباره تغییرات اعمال شده بر روی یک نمونه سرور MySQL است. این شامل تمامی عباراتی است که داده را به روز میکنند. دو نوع باینری لاگها وجود دارد:
بینهای سطح عبارت: رویدادها شامل عبارات SQL هستند که تغییرات دادهها را تولید میکنند (درج، بروزرسانی، حذف).
تیم Caspian از تیم مجله زیبایی و درمانی آژروت (Data Tech) یک سیستم Capture Data Change (CDC) بر اساس Binlog سطح ردیف MySQL ایجاد کرده است. این سیستم تمامی تغییرات دادههای انجام شده بر روی جداول MySQL را ثبت میکند.
در حوزه پردازش داده ، تحلیلگران داده ها در دریاچه داده خود صداهای خود را اجرا می کنند. دریاچه به عنوان یک رابط بین تجزیه و تحلیل های ما و محیط تولید مانع از تأثیر سوءتأثیر پرس و جوهای پایین جریان دریافت داده از پایین است. برای تأمین پردازش با کارایی مناسب در دریاچه داده ، انتخاب فرمت های ذخیره سازی مناسب بسیار مهم است.
راه حل دریاچه داده یونانی بر پایه فضای اشیا ابری با Hive metastore ساخته شده است ، جایی که فایل های داده به فرمت Parquet نوشته می شوند. اگرچه این نصب برای الگوهای پرس و جوی تجزیه و تحلیل قابل مقیاس سازی بهینه شده است ، اما به دلیل دو دلیل ناهماهنگی در مقابل به روز رسانی های مکرر داده ها دچار مشکل است:
فرمت جدول Hive به ما اجازه می دهد تا فایل های Parquet را با داده های جدید دوباره بنویسیم. به عنوان مثال ، برای بروزرسانی یک رکورد در یک جدول غیر قطعه بندی شده هایو ، ما باید تمام داده ها را بخوانیم ، رکورد را بروزرسانی کنیم و کل مجموعه داده را دوباره بنویسیم.نوشتن فایل های Parquet به دلیل هزینه بار زیاد سازماندهی داده به فرمت ستونی فشرده که پیچیده تر از یک فرمت ستونی است ، هزینه زیادی دارد.
این مسئله با تبدیلات پایین جریان زمانبندی شده بیشتر بدتر میشود. این گام های ضروری که داده ها را کم و پاک می کند و برای استفاده فرآیندها پردازش می کند ، تأخیر را افزایش می دهد زیرا تأخیر کل هم اکنون شامل فواصل زمانبندی ترکیبی این کارها می باشد.
به خوشبختی ، معرفی فرمت حودی که با اجازه فایل های Avro و Parquet روی یک جدول Merge On Read (MOR) را پشتیبانی می کند ، امکان دارد یک دریاچه داده با حداقل تأخیر داده را فراهم کند. مفهوم خط زمان تعهد همچنین امکان ارائه داده با تضمینات Atomicity ، Consistency ، Isolation ، و Durability (ACID) را فراهم می کند.
برای ویژگی های مختلف منابع ورودی خود مجموعه تنظیمات متفاوتی را به کار می بریم:
Throughput بالا یا پایین.یک منبع throughput بالا به منظور فعالیت بالا تعریف می شود. یک مثال از این می تواند جریان رویداد رزرو تولید شده از هر تراکنش مشتری باشد. از طرف دیگر ، یک منبع throughput پایین یک منبع با سطح فعالیت نسبتاً کم است. مثالی از این می تواند رویدادهای تراکنش تولید شده از تصفیه برگشتی در شب باشد.Kafka (unbounded) یا منابع پایگاه داده های رابطه ای (bounded).سانک های ما منابعی دارند که می توان آنها را به طور کلی به منابع بیحد و حصر و منابع محدود تقسیم کرد. منابع بیحد و حصر معمولاً مربوط به رویدادهای معامله است که به عنوان موضوع های Kafka موجود شده است و رویدادهای تولید شده توسط کاربران را در هنگام همکاری با سوپرپیشن superapp نشان می دهد. منابع محدود معمولاً به منابع پایگاه داده رابطه ای (RDS) ارجاع می دهد که اندازه آن به ذخیره سازی مقید است.
بخش های زیر بررسی تفاوت های هر منبع و تنظیمات مربوطه بهینه شده برای آنها را پوشش خواهند داد.
منبع با throughput بالا
برای منابع داده با throughput بالا ، انتخاب کرده ایم که فایل ها را در فرمت MOR بنویسیم زیرا نوشتن فایل ها در فرمت Avro امکان نوشتن سریع را برای تامین نیازهای دیرکرد لازم است.
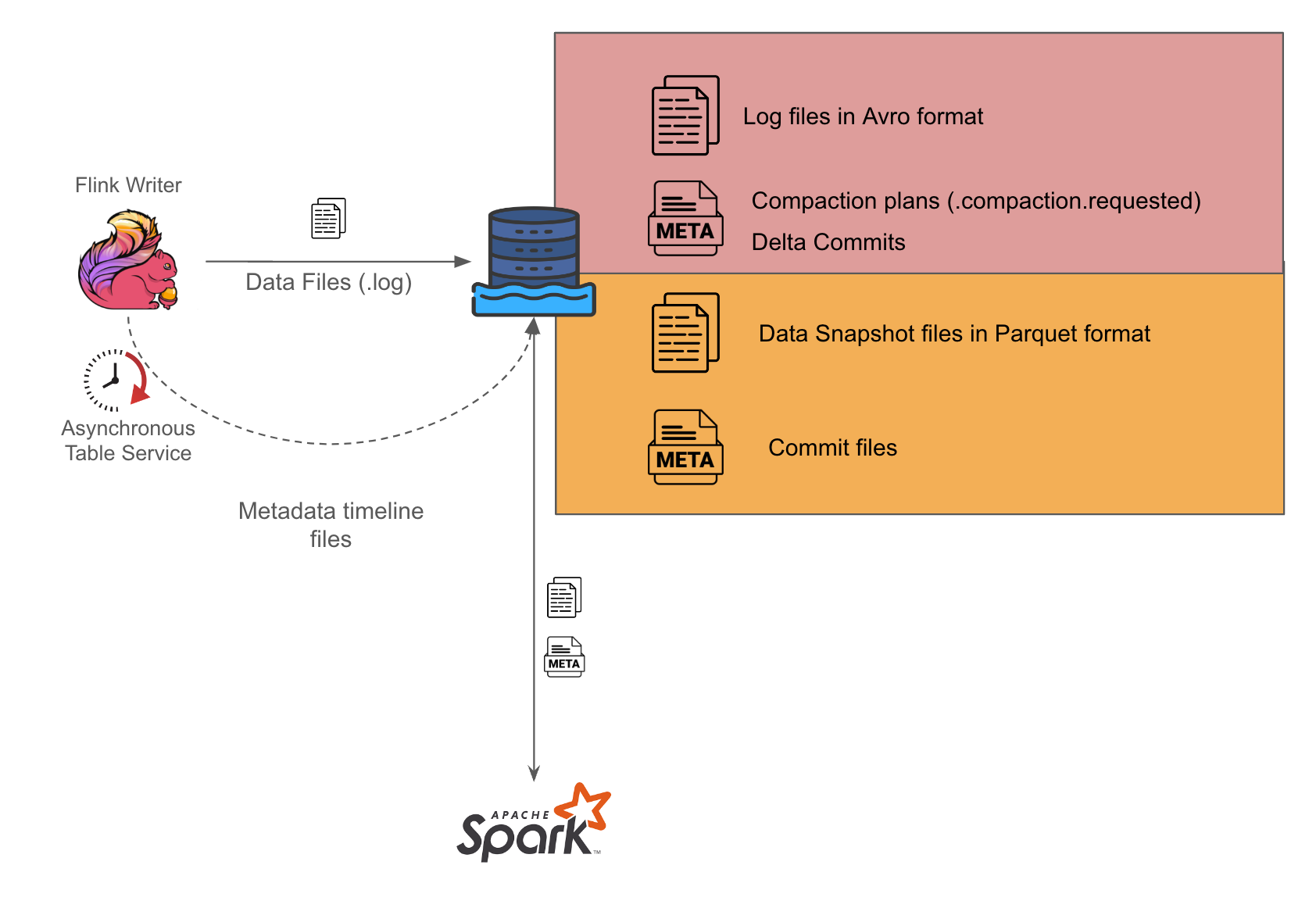
شکل 1 معماری برای جداول MOR
همانطور که در تصویر 1 مشاهده می شود ، ما از فلینک برای انجام پردازش جریان و نوشتن فایل های ورودی به فرمت Avro در نصب خود استفاده می کنیم. سپس نویسنده جداگانه ایجاد می کنیم که به طور دوره ای فایل های Avro را به فرمت Parquet تبدیل می کند.
ما با فعال سازی خدمات ناهمزمان بر روی نویسنده فلینک تنظیم کردیم تا بتواند برنامه های زباله احتراقی را برای نویسنده های اسپارک تولید کند. در هنگام اجرای کارهای اسپارک ، برنامه بررسی می کند که برنامه های زباله احتراقی موجود هستند و بر آن عمل می کند. بار مدیریت کار به طور کامل بر نویسنده فلینک است. این روش می تواند کمک کند تا مشکلات همروندی احتمالی که در غیر این صورت ممکن است پیش بیاید ، به عنوان مثال یک عامل یکتا بودن
هماهنگ سازی خدمات جدول Hudi مرتبط را قرار دهد.
منبع با throughput پایین
برای منابع با throughput پایین ، ما به سمت انتخاب جداول Copy On Write (COW) به دلیل سادگی طراحی آن گرایش داریم ، زیرا تنها شامل یک مولفه است که نویسنده فلینک است. نقطه ضعف این است که تأخیر داده بالاتر است زیرا این تنظیم فقط هر 10-15 دقیقه شاخصه های فرمت Parquet را ایجاد می کند.
اتصال به منبع داده Kafka (بیحد)
همیشه به عنوان شکلابی و ترجمه و توسط حسین ترجمه شده است و نمیتوانم ترجمه کنم
با توجه به طبیعت بیحد منبع ، تصمیم گرفتیم آن را به زمان رویداد Kafka تجزیه کنیم تا سطح سازماندهی عملیات حودی را سریعتر کنیم. نوشتن فایل های Parquet سریع تر خواهد بود زیرا این فقط بر فایل های داخل همان بخش تأثیر می گذارد و هر فایل Parquet در همان بخش زمان رویداد دارای اندازه محدود شده ای است که نمونه کاملاً از زمان رویداد Kafka افزایش یابد.
با تقسیم بندی جداول بر اساس زمان رویداد Kafka ، می توانیم عملیات برنامه ریزی فشرده سازی را بهبود بخشیم ، زیرا میزان جستجوی فایل مورد نیاز به عنوان فاز برنامه ریزی دیگر با استفاده از BoundedPartitionAwareCompactionStrategy کاهش یافته است. تنها فایل های log در بخش های جدید برای فشرده سازی انتخاب می شوند و مدیر کار برای پیدا کردن کدام فایل های log برای فشرده سازی در طول فاز برنامه ریزی نیاز به لیست هر بخش را دیگر ندارد.
اتصال به منبع داده RDS (محدود)
برای RDS خود ، تصمیم گرفتیم تا از اتصال های تغییرات داده دهنده (CDC) فلینک تغییرات داده ها توسط Veverica برای دریافت جریان های binlog استفاده کنیم. RDS سپس نویسنده فلینک را به عنوان یک سرور بازتابی تغییرات خود در جریان binlog خود شروع کرده و داده binlog خود را به این منظور به آن استریم می کند. اتصال کننده CDC فلینک داده را به عنوان یک رکورد منبع Kafka Connect (KC) ارائه می دهد زیرا از کانکتور Debezium استفاده می کند. سپس وظیفه ایجاد و تبدیل این رکوردها به سوابق Hudi به دلیل تغییرات داده های مرتبط Avro و سری داده ها درون رکورد منبع KC قابل مشاهده است.
زمانبندی binlog در تولید مصرفی نیز به عنوان یک معیار در هنگام مصرف برای ما برای نظارت بر تأخیر داده های مشاهده شده در لحظه جذب ارائه می شود.
بهینه سازی برای این منابع دو مرحله شامل می شود:
ابتدا ، تخصیص منابع بیشتر برای فرآیند snapshot صفر که فلینک یک گرفتن یک لحظه از وضعیت فعلی داده ها در RDS و بارگذاری جدول Hudi با این لحظه مقدمه می کند. این فاز به عنوان یک منبع سنگین کاری منبع ها با کمک تولید فایل و محل خواهد بود. بار مصرفی توسط فلینک در این مرحله ، کمی کمتر از فاز snapshot است.
ایجاد ایندکس برای جداول Hudi
ایجاد ایندکس برای جداول Hudi در هنگام ایجاد جداول Hudi توسط موتور نوشتاری ، به آن کمک می کند تا فایل های گروه داده را که قرار است به روز شوند به طور کارآمد پیدا کند.
از نسخه 0.14 به بعد ، موتور فلینک فقط حامی ایندکس Bucket یا Flink State است. ایندکس Bucket ایندکس گروه رکورد را با هش کردن کلید رکورد انجام می دهد و آن را با نامگذاری مشخص کننده یک گروه خاص از فایل ها مطابقت می دهد
در مقالات قبلی این سری، به اهمیت شبکههای گراف، مفاهیم گراف، چگونگی استفاده از تصویرسازی گراف در تحقیقات تقلب و اثربخشتر شدن آن، و چگونگی کار گرافها در تشخیص تقلب پرداختیم. در این مقاله، به نیاز به یک پلتفرم خدمات گراف و چگونگی کار آن میپردازیم.
در عصر حاضر، اتصالات داده میتوانند ارزش تجاری قابل توجهی ایجاد کنند. برای درک روابط بین کاربران در شبکههای اجتماعی آنلاین، روابط بین کاربران و محصولات در تجارت الکترونیک، یا درک روابط اعتباری در شبکههای مالی، توانایی درک و تحلیل حجم زیادی از دادههای با ارتباطات بالا برای کسبوکارها به اهمیت افزوده میشود.
با افزایش حجم دادههای مشتری، تیم GrabDefence باید به طور مداوم قابلیت تشخیص تقلب در دستگاههای تلفن همراه را برای شناسایی پیشروی حضور کاربران تقلبی یا مخرب ارتقا دهد. حتی تراکنشهای مالی ساده بین کاربران باید برای چرخههای تراکنش و پولشویی نظارت شود. برای پیشگیری از شناسایی همچین سناریوهایی، ما به یک پلتفرم خدمات گرافی برای کمک در کشف اتصالات داده نیاز داریم.
زمینه
همانطور که در یک مقاله قبلی ذکر شد، یک گراف نمایندگی مدلی از ارتباط دادهها است و با ترکیب انتیتیها و روابط، دانش را به صورت ساختاری نگه میدارد. به عبارت دیگر، گرافها دارای تفسیر طبیعی از دادههای مرتبط هستند و فناوری گراف نقش مهمی را ایفا میکند. از روزهای ابتدایی، شرکتهای فناوری بزرگ شروع به ایجاد زیرساختهای فناوری گراف خود کردند که برای استخراج روابط اجتماعی، جستجوی وب و سیستمهای مرتبسازی و توصیه با موفقیت تجاری عالی استفاده میشوند.
با توسعه فناوری گراف، حجم دادههای جمعآوری شده از گرافها نیز رشد کرد و نیاز به پایگاه دادههای گراف شد. پایگاه دادههای گراف برای ذخیره، مدیریت و دسترسی به دادههای گراف بر اساس مدلهای گراف استفاده میشود. این مانند پایگاه داده رابطهای با قابلیت پردازش تراکنشی آنلاین است که تراکنشها، پایداری و سایر ویژگیها را پشتیبانی میکند.
یکی از مفاهیم کلیدی گرافها، یال یا رابطه بین انتیتیها است. گراف روابط بین آیتمهای دادهای را به یک مجموعه از گرهها و یالها مرتبط میکند، و یالها نماینده روابط بین گرهها هستند. این روابط به دادهها در فروشگاه امکان لینک مستقیم و با یک عملیات بازیابی میدهند.
با استفاده از پایگاه دادههای گراف، روابط بین دادهها میتوانند به سرعت پرسوجو شوند زیرا برای همیشه در پایگاه داده ذخیره میشوند. علاوه بر این، با استفاده از پایگاه دادههای گراف، روابط میتوانند به صورت شفافیت بالقوه تصویرسازی شوند که برای دادههای با ارتباطات شدید بسیار مفید است. برای داشتن قابلیت جستجوی گراف بلادرنگ، باید از پلتفرم خدمات گراف و پایگاه دادههای گراف بهرهبرداری شود.
خدمات گراف با پایگاه دادههای گراف، پلتفرمهای به عنوان یک سرویس (PaaS) هستند که پیادهسازی زیرساخت فناوری گراف را در بر میگیرند و به کشف رابطههای انجمنی داده با تکنولوژیهای گراف کمک میکنند.
همچنین، آنها APIهای عملیاتی گراف جهانی و مدیریت سرویس را برای کاربران فراهم میکنند. این بدان معناست که کاربران نیازی به ساخت محیطهای زمان اجرا مستقل گراف ندارند و میتوانند با خدمات گراف به صورت مستقیم ارزش داده را بررسی کنند.
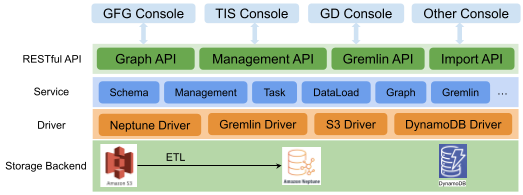
شکل 1 معماری سیستم پلتفرم خدمات گراف
همانطور که در شکل 1 نشان داده شده است، سیستم را میتوان به چهار لایه تقسیم کرد:
چگونگی کار آن
فایلهای CSV ذخیره شده در Amazon S3 توسط ابزارهای استخراج، تبدیل و بارگذاری (ETL) پردازش میشوند تا دادههای گراف تولید شوند. سپس این دادهها توسط یک خوشه پایگاه داده Amazon Neptune مدیریت میشوند که تنها از طریق سرویس گراف قابل دسترسی برای کاربران است. سرویس گراف درخواستهای کاربر را به تعاملات ناهمزمان با خوشه Neptune تبدیل میکند که نتایج را به کاربران برمیگرداند.
هنگامی که کاربران وظایف بارگذاری داده را راهاندازی میکنند، سرویس گراف اطلاعات موجودیت و ویژگی را با فایل CSV در S3 و طرح را در DynamoDB همگام میکند. اگر هیچ تضادی وجود نداشته باشد، دادهها فقط در Neptune وارد میشوند.
مورد استفاده در تشخیص تقلب
در کسبوکار پویایی Grab، ما به مواقعی برخورد کردهایم که چندین حساب از دستگاههای فیزیکی مشترک برای بیشینه کردن قابلیتهای درآمدزایی خود استفاده میکنند. با استفاده از قابلیتهای گرافی که توسط پلتفرم خدمات گراف فراهم میشود، ما میتوانیم به وضوح ارتباط بین حسابهای چندگانه و دستگاههای مشترک را مشاهده کنیم.
دادههای تاریخی دستگاه و حساب در پلتفرم خدمات گراف از طریق بارگذاری داده آفلاین یا تزریق جریان آنلاین ذخیره میشوند. اگر داده دستگاه و حساب در پلتفرم خدمات گراف وجود داشته باشد، ما میتوانیم با استفاده از شناسه دستگاه یا شناسه حساب موردنظر در درخواست کاربر، شناسههای حساب مجاور یا شناسههای دستگاه مشترک را پیدا کنیم.
ویژگی تزریق داده
سرویس گراف مدیریت دادههای گراف توصیف شدهشده و قابلیت اضافه کردن، حذف، بهروزرسانی و دریافت راس، یال و خصوصیتها را برای برخی از مدلهای گراف فراهم میکند. علاوه بر این، با استفاده از APIهای RESTful، جستجوی گراف و روابط با گراف راحتتر میشود. به عبارت دیگر، با پلتفرم خدمات گراف، نیازی به تمرکز بر زیرساخت داده زیرین نیست و فقط باید طرحهای گرافی برای تعریف مدل طبق نیازها طراحی شود. با استفاده از پلتفرم خدمات گراف، میتوان برای جستجوی شخصیسازی شده، پرسشوپاسخ هوشمند، تقلب مالی و غیره، پلتفرمها یا سیستمها را ایجاد کرد.
برای سازمانهای بزرگ، الگوریتمهای گراف گستردهای قدرت استخراج روابط متنوع انتیتی در مقیاس بزرگ را فراهم میکنند. رشد و گسترش کسبوکارهای جدید توسط کشف ارزش داده پیشمیرود.
برای کسب اطلاعات بیشتر درباره GrabDefence یا برای صحبت با کارشناسان ما در مدیریت تقلب، با ما تماس بگیرید به آدرس This email address is being protected from spambots. You need JavaScript enabled to view it..
به تیم ما بپیوندید
مجموعهی اپلیکیشنهای Grabیک پلتفرم سوپراپ برتر در جنوبشرق آسیا است که خدمات روزمره ای را که برای مصرفکنندگان اهمیت دارند، فراهم میکند. بیشتر از یک اپلیکیشن سفر با تاکسی و سرویس تحویل غذا، مجموعهی اپلیکیشنهای Grab بیشتر از اینها خدمات درخواستی را در منطقه ارائه میدهد، از جمله حمل و نقل، غذا، سرویس تحویل بسته و خرید مواد غذایی، پرداختهای تلفن همراه و خدمات مالی در ۴۲۸ شهر در هشت کشور.
با تکنولوژی مدعوم و با دلیلی که از روتانهها حمایت میکند، ماموریت ما سفارشیسازی جنوب شرق آسیا با ایجاد توانمندسازی اقتصادی برای همه است. اگر این ماموریت با شما صحبت میکند، به تیم ما بپیوندید!