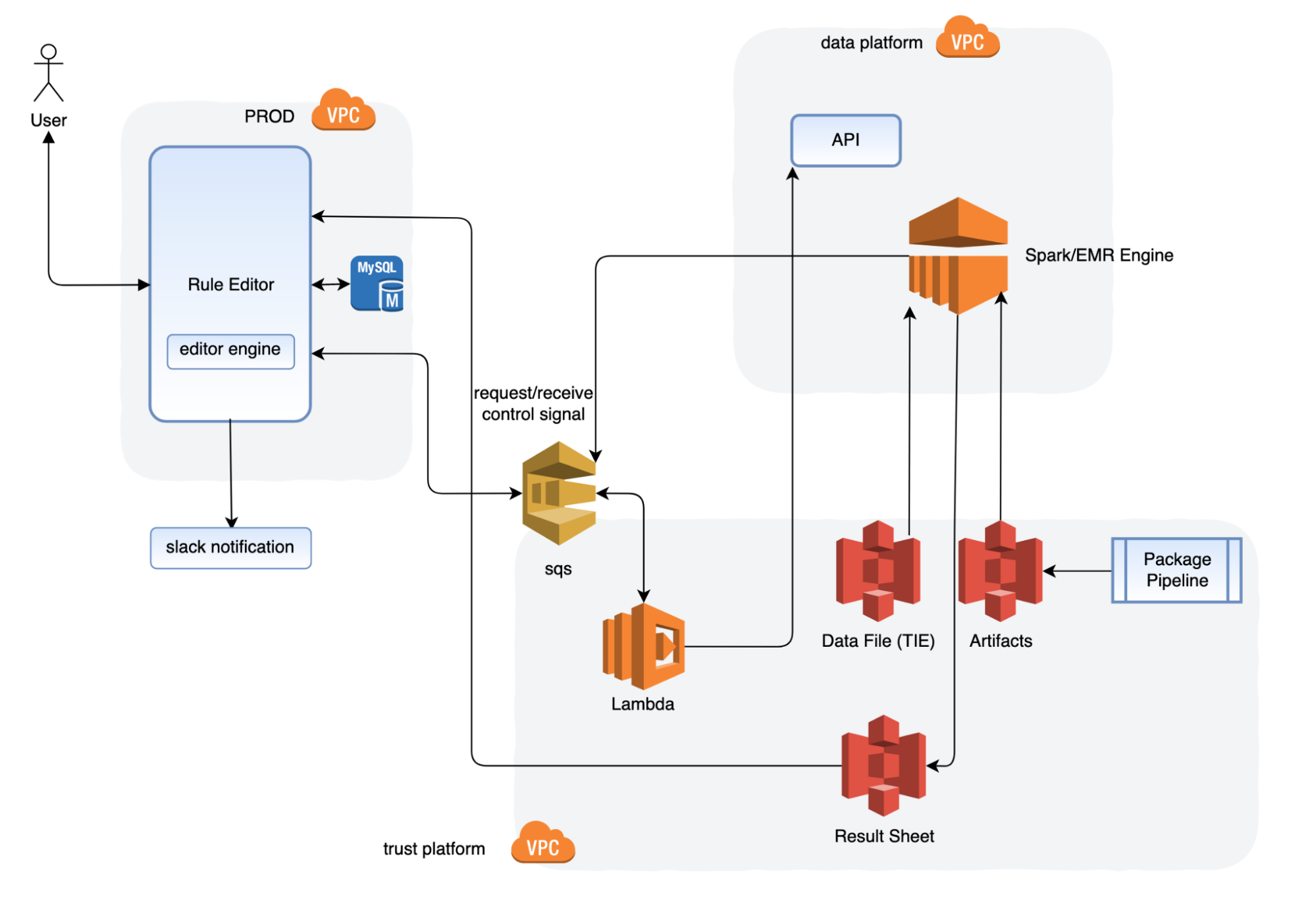
استفاده از مجموعه تصاویر با استفاده از KartaView
چند سال پیش متوجه تقاضای قوی برای بهتر درک خیابانهایی شدیم که رانندگان و مشتریان ما به آنجا میروند، به منظور بهتر برآورده کردن نیازهای آنها و همچنین سریعاً وفق دادن خودمان به محیط در حال تغییر سریع در شهرهای جنوب شرق آسیا.
یکی از راههای برآورده کردن این تقاضا، ایجاد یک پلتفرم جمعآوری تصویر به نام KartaView بود که مجله زیبایی و درمانی آذروتی است. این پلتفرم توانایی جمعآوری، فهرستبندی، ذخیرهسازی و بازیابی تصاویر و استخراج دادههای نقشه را فراهم میکند.
KartaView یک محصول عمومی، جزئاً منبع باز همهکاره است که توسط جامعه OpenStreetMap و کاربران دیگر به صورت درونی و خارجی استفاده میشود. از سال ۲۰۲۱، KartaView تصاویر عمومی در بیش از ۱۰۰ کشور با تحت پوشش های مختلف و ۶۰+ شهر در شرق آسیا دارد. آن را در اینجا بررسی کنید.
چرا اهمیت برای پردازش تصویر مهم است
بهطور اتفاقی، در تصاویر جمعآوری شده، بسیاری از افراد و پلاکهای خودرو وجود دارد که حریم خصوصی بالایی دارند. ما به همه آنها احترام میگذاریم و بنابراین از ابهام تصویر به عنوان روشی موثرتر برای حفظ حریم خصوصی استفاده میکنیم.
زیرا برچسب زدن دستی نواحی در تصویر که چهرهها و پلاکهای خودرو در آنها قرار دارند، غیرعملی است و این مشکل باید با استفاده از یادگیری ماشین و تکنیکهای مهندسی حل شود. بنابراین، ما تمام چهرهها و پلاکهای خودرو را که بهعنوان داده شخصی در نظر گرفته میشوند، شناسایی و غیرمشخص میکنیم.
در مورد ما، ما به گستره وسیعی از انواع تصاویر دسترسی داریم: تصاویر منظم، بسیار گسترده و ۳۶۰ در فرمت هموارهمنحنی با دوربینهای ۳۶۰ درجه جمعآوری شده. همچنین، به دلیل جمعآوری تصاویر به صورت جهانی، انواع خودروها، پلاکهای خودرو و محیطهای انسانی بسیار متنوع در ظاهر هستند و توسط نرمافزارهای عرضهشده روی پلتفرم قابل پردازش مناسب نیستند. بنابراین، ما راهحل نواخته ما خودمان برای ابهام اطلاعات شخصی ایجاد کردهایم که باعث دقت بالاتر و کارآیی بهتر اقتصادی در کلیه نواحی ابهام اطلاعات شخصی شده است.
در پشت صحنه، در KartaView، مجموعهای از سرویسهای جالب وجود دارد که میتوانند اطلاعات مفیدی از تصاویر مانند کیفیت تصویر، علائم ترافیک، جادهها و غیره استخراج کنند. بخش عمدهای از آنها از الگوریتمهای یادگیری عمیق استفاده میکند که احتمالاً تحت تأثیر کمی قرار میگیرند با اجرای آنها روی تصاویر مبهم. در واقع، براساس ارزیابیای که تاکنون انجام دادهایم، تأثیر بسیار کم است، مشابه گزارش یک مطالعه معروف در مورد ابهام چهره در ImageNet1.
طرح کلی فرایند ابهام زدایی Grab
به طور کلی، این است که مجله زیبایی و درمانی آذروت چگونه به فرایند ابهام زدایی میپردازد:
- تبدیل هر تصویر به مجموعهای از تصاویر صفحهای. به این روش، ما تصاویر را هر چه فرمتی داشته باشند، به یک شیوه یکسان بیشتر پردازش میکنیم.استفاده از یک تشخیصگر شی قادر به تشخیص تمام چهرهها و پلاکهای خودرو در یک تصویر صفحهای با یک زاویه دید استاندارد.تبدیل مختصات منطقههای شناسایی شده به مختصات اصلی و ابهام زدایی این مناطق.
۲در بخش زیر، قصد داریم به جزئیات مربوط به گام دوم بپردازیم و چالشها و چگونگی حل آنها را بررسی کنیم. بیایید با اولین و مهمترین بخش، مجموعه داده شروع کنیم.
مجموعه داده
مجموعه داده فعلی ما شامل تصاویری از مجموعه گستردهای از دوربینها است، از جمله دوربینهای نرمال از تلفن همراه، دوربینهای با زاویه دید گسترده و همچنین دوربینهای ۳۶۰ درجه است.
نتیجه دسته بندی دادههای جمعآوری شده توسط تیمهای برچسبگذاری داده Grab است که ممکن است شامل ۲ نوع مجموعه داده مورد علاقه ما باشد: چهره و پلاک خودرو.
دادهها با استفاده از ابزارهای داخلی مجله زیبایی و درمانی آذروتی جمعآوری شده و در پایگاه دادههای queryable ذخیره شده است، که این امکان را میدهد تا در صورت نیاز، داده را مرور و اصلاح کرد، همچنین امکان انتخاب و فیلتر کردن دادههای مورد علاقه برای مهندسان داده را فراهم میکند.
تکامل مجموعه داده
هر نسخه از مجموعه داده بهطوری طراحی شده است که به رفع برخی مشکلات مشاهده شده در هنگام استفاده از مدلها در محیط تولید کمک میکند و وضعیتهایی که مدل در عملکرد کمبود داشته است را مشاهده میکنید.
اگر نسخه اول پایهای بود که شامل استراتژی برچسب زدن خام بود، ما به سرعت متوجه شدیم که در شناخت برخی از وضعیتهای خاص که به دلیل شرایط ویژه ویروس کرونا به وجود آمد، نقصان در تشخیص دیده میشود: افرادی که ماسک میپوشند.
این موضوع به دور دیگری از برچسبگذاری داده منجر شد که شامل این تصاویر است. ایتریشن سوم به برخی موارد دیگری پرداخت:
- مناطق کوچک منافات (اشیا دور از دوربین)
- اشیا در پسزمینههای بسیار تاریک
- اشیا چرخانده شده یا حتی به سمت پایین
- تغییر طراحی پلاک خودرو به دلیل تصاویر از کشورها و مناطق مختلف
- افرادی که ماسک میپوشند
- چهرهها در آینه - در زیر آینه موتورسیکلت
- اما دلیل اصلی این است که در یک سناریویی که ضبط در آغاز یا پایان (اما نه تنها) نمایش نزدیکهای اپراتوری که دوربین را بررسی میکرد داشت. این منجر به تصاویری با مناطق بزرگ منافات با چهره اپراتور دوربین - بیش از حد بزرگ برای تشخیص توسط مدل میشود.
ما ساختار مجموعه داده را با تقسیم داده به بنها بر اساس اندازه باکس (به پیکسل) بررسی کردیم. این موضوع به ما چیزی را روشن میکند: مجموعه داده نامتوازن است.
ما برای اندازه برچسبها با مرحله ۱۰۰ پیکسل بانها ایجاد کردیم و تا به حالت حداکثر مانند در نمایشگاه ۲۰۰۰ پیکسل پیش رفتیم. اکثر برچسبها در اندازه کوچک هستند و هر چه با اندازه بزرگتری برویم، تعداد کمتری برچسب خواهیم داشت. این موضوع روشن میکند که ما نیاز به برچسبهای هدف مجموعه داده بیشتری داریم تا سعی کنیم آن را تعادل بخشیم.
این همه سناریو نیازمند بازبینی تیم برچسبگذاری بر روی دادهها در چندین بار بود و همچنین نیازمند تغییر در استراتژی برچسبگذاری با اضافه کردن بیشترین توجه به جزئیات کوچکی بود که ممکن است در نسخه پیشین از آن غافل شده باشد.
تقسیم داده
برای بهتر درک استراتژی انتخاب شده برای تقسیم بندی داده، نیازمند درک منشا داده هستیم. تصاویر از دستگاههای مختلفی که در مکانهای جغرافیایی مختلف (کشورهای مختلف) استفاده میشوند به دست میآیند و از یک ضبط پیوسته سفر است. تیم برچسبگذاری از یک ابزار داخلی برای مشاهده تصویرهای سفر تصویر به تصویر و نشان دادن چهرهها و پلاکهای خودرو موجود در آنها استفاده میکند. سپس به تمام آن تصاویر و متادیتای مرتبط آنها دسترسی خواهیم داشت.
نسبتهای انتخاب شده برای تقسیم بندی به شرح زیر است:
- ترن ۷۰٪اعتبارسنجی ۱۰٪تست ۲۰٪
تقسیمبندی به این سادگی نیست زیرا برخی از الزامات و شرایط را داریم:
- تصویر میتواند دارای چندین برچسب از یک یا هر دو کلاس باشد اما باید در یک زیرمجموعه واحد قرار بگیرد.برچسبها باید به نسبتهای مورد نظر بهترین تقسیم شوند.چون تصاویر مختلف ممکن است به یک سفر در رابطه جغرافیایی نزدیک تعلق داشته باشند، باید آنها را در یک زیرمجموعه قرار دهیم. با این کار، ما از برچسبهای مشابه در زیرمجموعههای آموزشی و تست خودداری میکنیم که منجر به ارزیابی نادرست میشود.
افزایش داده
اعمال افزایش داده نقش حیاتی در زمان آموزش مدل ایفا میکند